Sololearn 自学机器学习 15 ROC 曲线
如何构建ROC曲线
ROC曲线是特异性和敏感性(Specificity vs Sensitivity)的图表。我们构建一个逻辑回归模型,然后计算每个可能阈值的特异性和敏感性。每个预测概率都是一个阈值。如果我们有5个数据点,其预测概率分别为:0.3, 0.4, 0.6, 0.7, 0.8,我们将使用这 5 个值作为阈值。
请注意,实际上我们绘制的是敏感性与(1 - 特异性)的关系图。这样做的主要原因是标准化。
让我们首先看一下构建 ROC 曲线的代码。Scikit-learn 有一个 roc_curve 函数让我们使用。该函数接受模型的真实目标值和预测概率。
我们首先使用模型上的 predict_proba 方法获取概率。然后调用 roc_curve 函数。roc_curve 函数返回一个假阳性率 (False Positive) 数组,一个真阳性率 (True Positive) 数组和阈值 (Threshold)。假阳性率是 1 - 特异性( x 轴 ),真阳性率是敏感性的另一种表达( y 轴 )。图中不需要阈值值。
这是在 matplotlib 中绘制 ROC 曲线的代码。请注意,我们还有绘制对角线的代码。这可以帮助我们直观地看出我们的模型离随机预测的模型有多远。
我们假设我们已经有了一个已分割成训练集和测试集的数据集。
model = LogisticRegression() |
You have to import roc_curve to run the code
from sklearn.metrics import roc_curve |
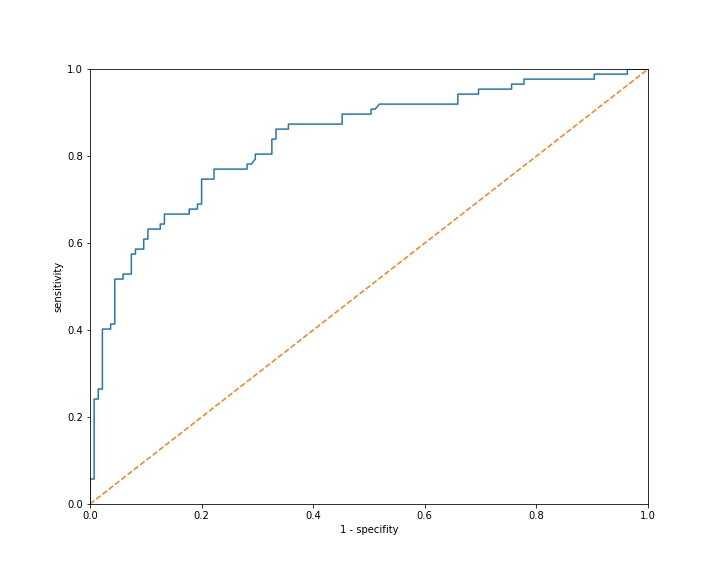
因为我们不使用阈值来构建图形,所以图形并不能告诉我们每个可能模型的阈值是多少。
In case you are having issues understanding the concept of ROC curves, watch the video in the link below 👇
ROC曲线解释
ROC曲线显示的不是单个模型的性能,而是许多模型的性能。每个阈值的选择对应一个不同的模型。
让我们看一下突出显示这些点的ROC曲线。

每个点 A、B 和 C 表示具有不同阈值的模型。
模型A的敏感性为 0.6,特异性为 0.9(请记住图表显示的是 1 减去 特异性)。
模型B的敏感性为 0.8,特异性为 0.7。
模型C的敏感性为 0.9,特异性为 0.5。
在这些模型之间如何选择将取决于我们情境的具体情况。
曲线越靠近左上角,性能越好。曲线不应该低于对角线,因为那意味着它的性能比随机模型还差。
请记住,我们的目标是最大化这两个值。一个理想的模型将具有敏感性为 1 和特异性为 1,因此敏感性 + 特异性的总和为2。
- 模型A的敏感性为 0.6,特异性为 0.9,总和为 1.5;
- 模型B的敏感性为 0.8,特异性为 0.7,总和为 1.5;
- 模型C的敏感性为 0.9,特异性为 0.5,总和为 1.4。
因此,我们可以说模型 A 和模型 B 的表现相当,但模型 C 稍逊一筹,因为其敏感性和特异性之和较低。你可以看到 A 和 B 都与左上角等距,而 C 则更远。我猜你可能仍然会选择使用 C,这取决于具体情况。例如,如果你确实需要一个敏感性(召回率)更高的模型,即使特异性 / 精确度较低。
我认为这确实取决于具体情况,不一定是敏感性和特异性之和越高模型就越好。在某些情况下,你可能只需要高特异性,而不关心敏感性。最终取决于目标。
从 ROC 曲线中选择一个模型
当我们准备最终确定我们的模型时,我们必须选择一个单一的阈值来进行预测。ROC 曲线是帮助我们为我们的问题选择理想阈值的一种方式。
让我们再次看一下我们突出显示三个点的 ROC 曲线:
如果我们处于一个情况:其中所有正类别的预测都正确更重要,而不是我们捕捉所有正类别的情况(这意味着我们要正确预测大多数负类别),我们应该选择特异性较高的模型(模型 A)。
如果我们处于一个情况,其中尽可能多地捕捉正类别的情况更为重要,我们应该选择敏感性较高的模型(模型 C)。
如果我们希望在敏感性和特异性之间取得平衡,我们应该选择模型 B。
原文
If we are in a situation where it’s more important that all of our positive predictions are correct than that we catch all the positive cases (meaning that we predict most of the negative cases correctly), we should choose the model with higher specificity (model A).
If we are in a situation where it’s important that we catch as many of the positive cases as possible, we should choose the model with the higher sensitivity (model C).
If we want a balance between sensitivity and specificity, we should choose model B.
跟踪所有这些术语 (terms) 可能有点棘手。即使是专业人士也不得不再次查阅它们,以确保他们正确解释这些值。
从 ROC 曲线中选择一个模型的练习
假设我们有一个用于预测信用卡欺诈的模型。如果我们在某人的账户上检测到欺诈交易,我们将禁用他们的信用卡。因此,我们希望确保在做出正类别预测时我们是准确的。在ROC图中的这三个模型中,哪一个在这种情况下更可取?
查看答案和解释
A
In the case of predicting credit card fraud, where it’s crucial to ensure accuracy when making positive predictions (minimizing false positives), a higher specificity is preferred. Therefore, Model A, which has higher specificity, would be preferred in this scenario. This is because a higher specificity indicates a lower false positive rate, meaning that the model is less likely to incorrectly flag legitimate transactions as fraudulent.
在预测信用卡欺诈的情况下,当确保在进行正类别预测时的准确性至关重要(最小化假正例),更高的特异性是首选的。因此,在这种情况下,更倾向于选择具有较高特异性的模型 A。这是因为较高的特异性表示较低的假正例率,意味着该模型更不太可能将合法交易错误地标记为欺诈。
曲线下面积 Area Under the Curve
有时我们希望使用ROC曲线来比较两个不同的模型。这里是两个模型的ROC曲线比较。
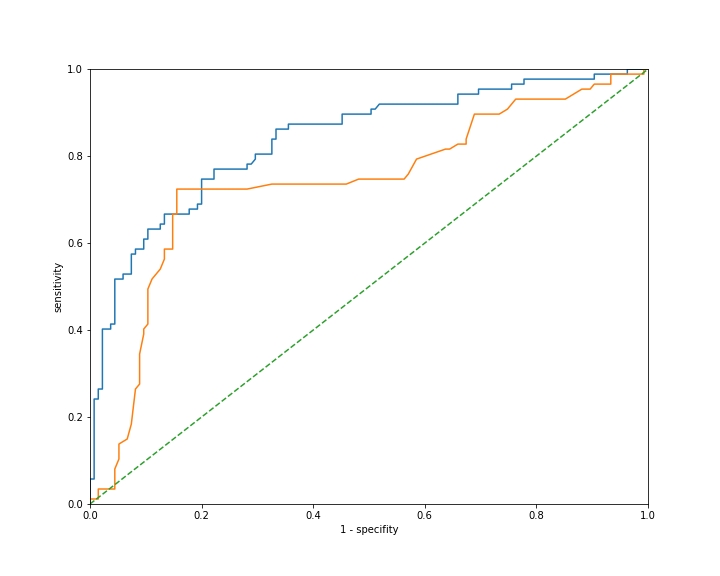
你可以看到蓝色曲线的性能优于橙色曲线,因为蓝线几乎总是在橙线上方。
为了获得这个的经验性度量,我们计算曲线下面积,也称为 AUC(Area Under the Curve)。这是 ROC 曲线下面的面积,取值范围在 0 到 1 之间,数值越高越好。
由于 ROC 是各种具有不同阈值的逻辑回归模型的图表,AUC 并不衡量单个模型的性能。它提供了逻辑回归模型的整体性能的一般概念。要获得单一模型,仍然需要找到问题的最佳阈值。
让我们使用 scikit-learn 帮助我们计算曲线下面积。我们可以使用 roc_auc_score 函数。
from sklearn.metrics import roc_auc_score |
这里是两条曲线的AUC值:
- 蓝色 AUC:0.8379
- 橙色 AUC:0.7385
你可以通过经验性的方式看到蓝色的效果更好。
我们可以使用 roc_auc_score 函数计算 Titanic 数据集上逻辑回归模型的 AUC 分数。我们构建了两个逻辑回归模型,model 1 具有 6 个特征,model 2 只有 Pclass 和 male 两个特征。我们看到 model 1 的 AUC 分数更高。
运行此代码以查看结果。
import pandas as pd |
重要的是要注意,这个指标告诉我们逻辑回归模型在我们的数据上总体表现如何。由于 ROC 曲线显示了多个模型的性能,AUC 并不衡量单个模型的性能。
 微信
微信 支付宝
支付宝










