Sololearn 自学机器学习 13 训练与测试
过拟合(Overfitting)
got to see the answers to the quiz before we gave it the quiz — The best analogy used to explain overfitting.
让学生在我们出考试题之前已经看到了考试答案。这是解释过拟合的最佳类比。
到目前为止,我们已经用所有的数据构建了一个模型,然后看了一下它在相同数据上的表现如何。这实际上是在人为地夸大我们的数字,因为我们的模型在实际上在我们给它测验之前就已经看到了测验的答案。这可能导致我们所说的过拟合。过拟合是指我们在模型已经看过的数据上表现良好,但在新数据上表现不佳。(Overfitting is when we perform well on the data the model has already seen, but we don’t perform well on new data.)
我们可以从视觉上看出一个过拟合的模型如下。这条线试图过于贴近每个数据点的正确一侧,但却忽略了数据的本质。
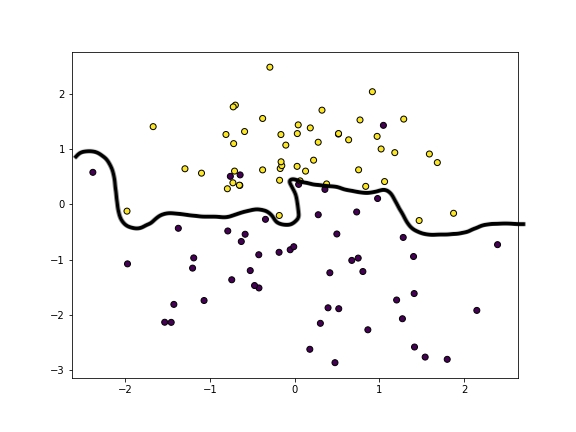
在图表中,您可以看到我们在将黄点放在顶部和紫点放在底部方面做得相当好,但它并没有捕捉到正在发生的事情。一个单独的异常点可能会严重影响线的位置。虽然模型在已经看过的数据上得分很高,但在新数据上表现良好的可能性较小。
我们的数据集中拥有的特征越多,我们就越容易出现过拟合的情况。
另一种看待过拟合模型的方式就像是一个学生在课堂上记住老师教的例子。如果问这样的学生任何一个例子中的问题,他会表现得非常好。但如果问学生一个完全不同的问题,不是例子中的任何一个,他就会表现得很差。这样的学生并没有在学习,他并不真正理解他所学的内容…他只是在死记硬背。大多数数据包含的观察结果都是离群值(outliner)和噪声(noise)。它们可能是作为数据特异性(idiosyncrasies)的一部分而自然发生(occur naturally),也可能是由于记录错误导致的。过拟合模型是一种过于受噪声影响的模型,因此,它不是在学习纯粹的隐藏模式(忽略噪声),而是开始学习噪声。它过于适应训练集,因此在测试集上表现不佳。在机器学习模型中,过拟合的模型实际上并没有从数据中学到东西,而只是死记硬背。请记住,它被称为机器学习,而不是机器记忆。😎
训练集(Training set)和 测试集(Testing set)
我们在 课程一开始 ,就分别提供了 train.csv训练集 和 test.csv 测试集,并且从中计算出对应的模型评估分数。那么从现在开始,您需要重新下载 titanic.csv 点此下载,由 sololearn 提供的数据集来进行操作,确保自己对结果没有误差。很抱歉为您带来了不便。
为了对模型进行公正评估,我们想知道我们的模型在尚未见过的数据上的表现如何。
在实际操作中,我们的模型将在我们不知道答案的数据上进行预测,因此我们想评估模型在新数据上的表现,而不仅仅是在已经见过的数据上。为了模拟在新的未见过的数据上进行预测,我们可以将数据集分为训练集和测试集。训练集用于构建模型,而测试集用于评估模型。我们在构建模型之前分割数据,因此模型对测试集一无所知,我们将对其进行公正评估。
如果我们的数据集中有 200 个数据点,将其分为训练集和测试集可能如下所示。
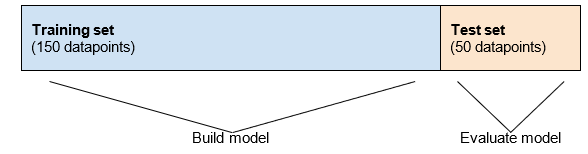
标准的划分是将我们的数据的 70-80% 放入训练集,而将 20-30% 放入测试集。在训练集中使用较少的数据意味着我们的模型将没有太多数据可供学习,因此我们希望尽可能多地提供数据,同时仍然留有足够的数据进行评估。
在 SkLearn 中的训练和测试
Scikit-learn中内置了一个函数,用于将数据分为训练集和测试集。
假设我们有一个包含特征的二维numpy数组 X 和一个包含目标的一维 numpy 数组 y,我们可以使用 train_test_split 函数。它会将每个数据点随机放入训练集或测试集。默认情况下,训练集占数据的 75%,测试集占剩余的 25%。让我们来实现这个功能
import pandas as pd |
得到的结果为:
whole dataset: (887, 6) (887,) |
我们可以看到,在我们的数据集中有 887 个数据点,其中 665 个在训练集中,222 个在测试集中。数据集中的每个数据点都仅使用一次,要么在训练集中,要么在测试集中。请注意,我们的数据集中有 6 个特征,因此在训练集和测试集中仍然有 6 个特征。
我们可以通过使用 train_size 参数来更改训练集的大小。例如,train_test_split(X, y, train_size=0.6) 将使60%的数据位于训练集中,40%位于测试集中。
在 SkLearn 中的训练和测试提问
我们有一个包含100个数据点和4个特征的二维numpy数组X,以及一个包含100个目标值的一维数组y。这段代码的输出是什么?
X_train, X_test, y_train, y_test = train_test_split(X, y) |
输出是训练集的特征矩阵(X_train)和目标数组(y_train)的形状。
查看答案和解释
(75, 4) (75, ) |
使用训练集构建 Scikit-learn 模型
现在我们知道如何将数据分为训练集和测试集,我们需要修改构建和评估模型的方式。所有的模型构建都是使用训练集完成的,而所有的评估都是在测试集上完成的。
在上个模块中,我们构建了一个模型并在同一数据集上进行了评估。现在我们使用训练集构建模型。
model = LogisticRegression() |
然后我们使用测试集评估模型。
print(model.score(X_test, y_test)) |
事实上,我们在之前部分计算的所有指标都应该在测试集上计算。完整代码如下:
import pandas as pd |
我们的准确率(Accuracy)、精确度(Precision)、召回率(Recall)和 F1 分数(F1 Score)的值实际上与在使用整个数据集时的值非常相似。这表明我们的模型没有过拟合!
如果您运行代码,您会注意到每次都会得到不同的分数。这是因为训练测试拆分 train_test_split 是随机进行的,取决于哪些点落入训练集和测试集,分数将不同。当我们学习交叉验证时,我们将看到更准确的衡量这些分数的方法。
使用训练集构建 Scikit-learn 模型的练习
假设我们有一个包含特征的二维numpy数组X和一个包含目标值的一维numpy数组y。
我们从以下开始:
X_train, X_test, y_train, y_test = train_test_split(X, y) |
以下哪种是在scikit-learn中正确使用训练集和测试集的方式?
model.fit(X_train, y_train) print(model.score(X_train, y_train))model.fit(X_test, y_test) print(model.score(X_train, y_train))model.fit(X, y) print(model.score(X_test, y_test))model.fit(X_train, y_test) print(model.score(X_train, y_test))model.fit(X_train, y_train) print(model.score(X_test, y_test))
查看答案
答案是 5 model.fit(X_train, y_train) print(model.score(X_test, y_test)),我们用 train 集合用于训练模型,而用 test 集合用于评估模型。
使用随机种子
正如我们在前一部分中注意到的,当我们随机将数据分割为训练集和测试集时,每次运行代码时,每个集合中的数据点都会不同。这是随机性的结果,我们需要它是随机的才能有效,但这有时会使测试代码变得困难。
例如,每次运行以下代码时,我们都会得到不同的结果。
from sklearn.model_selection import train_test_split |
为了每次都获得相同的拆分,我们可以使用 random_state 属性。我们选择一个任意的数字,并且每次运行代码时,我们将获得相同的拆分。
from sklearn.model_selection import train_test_split |
The random state is also called a seed.
 微信
微信 支付宝
支付宝










