Sololearn 自学机器学习 16 K-Fold 交叉验证
k-fold 交叉验证是一种评估机器学习模型性能的方法。在训练和验证过程中,数据集被分成 k 个折叠,模型 k 次训练和验证,每次使用不同的折叠作为验证集,其余作为训练集。这有助于更准确地评估模型的性能。
关于训练集和测试集的担忧
我们进行评估是因为我们想要准确地衡量模型的性能。如果我们的数据集很小,那么我们的测试集就会很小。因此,它可能不是数据点的良好随机分配,并且由于随机原因最终在我们的评估集中得到易于或难以处理的数据点。
由于我们的目标是获得我们度量指标(准确度 Accuracy、精确度 Precision、召回率 Recall 和 F1 分数)的最佳度量,我们可以比单一训练和测试集做得更好一些。
回顾一下我们的训练和测试集拆分如下。
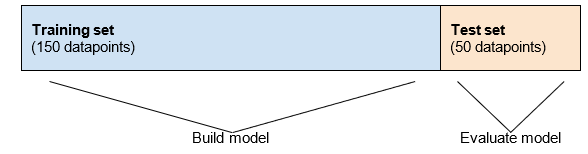
正如我们所见,训练集中的所有值都没有用于评估。使用训练集构建模型然后用训练集进行评估是不公平的,因为这样我们无法得到模型性能的完整图片。
为了从经验上看到这一点,让我们尝试运行 13 训练与测试 中执行训练/测试拆分的代码。我们将重新运行它几次并查看结果。每一行都是不同的随机训练/测试拆分的结果。
| Rum times | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| 1 | 0.83 | 0.79 | 0.75 | 0.77 |
| 2 | 0.79 | 0.80 | 0.63 | 0.71 |
| 3 | 0.79 | 0.79 | 0.68 | 0.73 |
| 4 | 0.84 | 0.75 | 0.73 | 0.74 |
| 5 | 0.80 | 0.81 | 0.60 | 0.69 |
您可以看到每次运行时,我们得到的度量值都不同。准确度从 0.79 到 0.84,精确度从 0.75 到 0.81,召回率从 0.63 到 0.75。这些是广泛范围的值,仅取决于测试集中最终包含哪些数据点是幸运还是不幸运。
如果您想自己运行并查看指标的变化值,以下是代码。
import pandas as pd |
{0: .5f}是使用 Python 的字符串格式的占位符。Python将使用.format(*args)的参数从提交的值替换这些占位符,其中:
0表示将此占位符替换为第一个参数。从 Python 3.1 开始,您无需包括此 0,但如果要在字符串中多次使用相同的参数,则这些是必需的。:将替换字段名称与格式规范分隔开。.5表示将小数部分四舍五入到5位数字,f表示我们正在处理浮点数。在大多数情况下,Python 最新的 f-strings 是更好的字符串格式选择。以下是相同行的 f-string 格式:
print(f"precision: {precision_score(y_test, y_pred):.5f}")有关字符串格式的更多信息:https://realpython.com/python-formatted-output/
与单一训练 / 测试拆分不同,我们将数据多次拆分为训练集和测试集。
多个训练和测试集
我们在前面的部分学到,根据我们的测试集,我们可以得到评估指标的不同值。我们希望获得对我们的模型整体表现的度量,而不仅仅是在一个特定的测试集上表现如何的度量。
与其只将数据的一部分作为测试集,不如将我们的数据集分成5个部分。假设我们的数据集中有200个数据点。

这5个部分中的每一个都将作为一个测试集。当第1个部分是测试集时,我们将剩下的4个部分作为训练集。因此,我们有5个训练和测试集,如下所示。
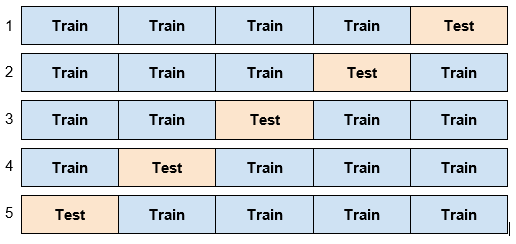
每一次我们都有一个20%的测试集(40个数据点)和一个80%的训练集(160个数据点)。
每个数据点都恰好在一个测试集中。
建立和评估多个训练和测试集
在前一部分,我们看到如何创建5个不同训练集的测试集。
现在,对于每个训练集,我们构建一个模型并使用相关的测试集进行评估。因此,我们构建5个模型并计算5个分数。
假设我们正在尝试计算模型的准确度分数。
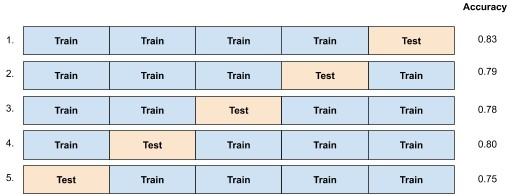
我们将准确度报告为这5个值的平均值:
如果我们只进行了单一的训练和测试集,并且随机选择了第一个,我们将报告准确度为0.83。如果我们随机选择了最后一个,我们将报告准确度为0.75。对所有这些可能的值取平均有助于消除数据点落入哪个测试集的影响。
只有在数据集较小的情况下,您才会看到这么大的差异。对于较大的数据集,我们通常只是简单地进行训练和测试集的划分。
创建多个训练和测试集的这个过程称为 k 折交叉验证 (k-fold cross validation) 。k 是我们将数据集分成的块数。标准数是 5,就像我们在上面的示例中所做的那样。
我们在交叉验证中的目标是获得我们度量指标(准确度、精确度、召回率)的准确度量。我们构建额外的模型,以便对我们计算和报告的数字感到有信心。
在k折交叉验证中的最终模型选择
现在我们建立了 5 个模型而不只是一个。我们如何决定使用哪个单一模型?
这 5 个模型仅用于评估目的,以便我们可以报告度量值。实际上,我们并不需要这些模型,而是想要构建可能的最佳模型。可能的最佳模型将是一个使用所有数据的模型。因此,我们跟踪我们计算的评估指标的值,然后使用所有数据构建一个模型。
这可能看起来非常浪费,但计算机有大量的计算能力,因此值得多使用一些来确保我们报告了正确的评估指标值。我们将使用这些值来做出决策,因此正确计算它们非常重要。
在构建模型时,计算能力 (computing power) 对于大型数据集可能是一个问题。在这些情况下,我们只是进行训练测试拆分。
在 SkLearn 中的 KFold 类
Scikit-learn 已经实现了将数据集分成k个块并创建k个训练和测试集的代码。
为简单起见,让我们以一个只有 6 个数据点和2个特征的数据集为例,并在该数据集上进行 3 折交叉验证。我们将从 Titanic 数据集中取前 6 行,只使用 Age 和 Fare 列。
X = df[['Age', 'Fare']].values[:6] |
我们首先实例化一个 KFold 类对象。它接受两个参数:n_splits(这是 k,要创建的块数)和 shuffle (是否对数据的顺序进行随机化)。通常最好对数据进行洗牌,因为数据集经常处于排序的状态。
kf = KFold(n_splits=3, shuffle=True) |
为了实现相同的随机状态,您可以将
random_state=value作为参数传递给KFold,其中value是用于确定k-fold拆分的随机状态的固定数字。
KFold类有一个 split 方法,用于为我们的数据创建 3 个拆分。
让我们看一下 split 方法的输出。 split 方法返回一个生成器,因此我们使用 list 函数将其转换为列表。
list(kf.split(X)) |
kf.split(X)返回的是索引,而不是数据点。
完整代码
from sklearn.model_selection import KFold |
正如我们所看到的,我们有 3 个训练和测试集,符合预期。第一个训练集由数据点 0、2、3、5 组成,测试集由数据点 1、4 组成。
拆分是随机进行的,因此每次运行代码时都可以看到不同的数据点集。
使用 Folds 创建训练和测试集
我们使用 KFold 类和 split 方法获取了每个拆分中的索引。现在让我们使用该结果来获得我们的第一个(共3个)训练 / 测试拆分。
首先,让我们取出第一个拆分。
splits = list(kf.split(X)) |
输出:
# (array([0, 2, 3, 5]), array([1, 4])) |
第一个数组是训练集的索引,第二个是测试集的索引。让我们创建这些变量。
train_indices, test_indices = first_split |
输出:
# training set indices: [0, 2, 3, 5] |
现在我们可以根据这些索引创建 X_train、y_train、X_test 和 y_test。
X_train = X[train_indices] |
如果我们打印出每个变量,我们将看到 X_train 中有四个数据点及其目标值,而剩下的两个数据点在 X_test 中,它们的目标值在 y_test 中。
print("X_train") |
from sklearn.model_selection import KFold |
运行此代码以查看结果。在这一点上,我们有与使用 train_test_split 函数相同格式的训练和测试集。
这可能会让人感到困惑。个人而言,我在提供的代码中添加了一些打印语句,以便更容易看到每个步骤的发生情况:
# 这提供了索引,而不是实际值。 |
这段代码将打印出每个步骤中发生的情况,包括拆分的索引和训练/测试集的索引。
构建模型
现在我们可以使用训练和测试集构建模型并进行预测,就像之前一样。让我们回到使用整个数据集(因为4个数据点不足以构建一个像样的模型)。
以下是构建并在5折交叉验证的第一个折叠上评分模型的完整代码。请注意,拟合和评分模型的代码与使用train_test_split函数时完全相同。
请尝试运行它:
from sklearn.model_selection import KFold |
到目前为止,我们基本上只是进行了一次训练 / 测试拆分。为了进行 k 折交叉验证,我们需要使用其他 4 个拆分中的每一个来构建模型并评分模型。
循环遍历所有的折叠
我们之前是一次处理一个折叠,但实际上我们希望循环遍历所有的折叠以获取所有的值。我们将前面部分的代码放在for循环中。
scores = [] |
输出:
# [0.75847, 0.83146, 0.85876, 0.76271, 0.74011] |
由于我们有 5 个折叠,我们得到 5 个准确度值。回想一下,为了得到一个单一的最终值,我们需要取这些值的平均值。
print(np.mean(scores)) |
输出:
# 0.79029 |
现在我们已经计算了准确度,我们不再需要我们构建的 5 个不同模型。对于将来的使用,我们只想要一个单一的模型。为了获得可能的最佳单一模型,我们在整个数据集上构建一个模型。如果有人问起这个模型的准确度,我们使用通过交叉验证计算的准确度(0.79029),即使我们实际上还没有使用测试集测试过这个特定模型(Model built with whole dataset)。
final_model = LogisticRegression() |
完整代码
from sklearn.linear_model import LogisticRegression
import pandas as pd
import numpy as np
df = pd.read_csv('https://kingsmai.github.io/uploads/@files/datasets/titanic/titanic.csv')
df['male'] = df['Sex'] == 'male'
X = df[['Pclass', 'male', 'Age', 'Siblings/Spouses', 'Parents/Children', 'Fare']].values
y = df['Survived'].values
scores = []
kf = KFold(n_splits=5, shuffle=True)
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model = LogisticRegression()
model.fit(X_train, y_train)
scores.append(model.score(X_test, y_test))
print(scores)
print(np.mean(scores))
final_model = LogisticRegression()
final_model.fit(X, y)
每次运行代码都可以期望得到稍微不同的值。KFold 类每次都会随机拆分数据,因此不同的拆分将导致不同的分数,尽管你应该期望这 5 个分数的平均值通常大致相同。
cross_val_score
sklearn 中的 cross_val_score 函数是一种方便的方法,可以在不必手动迭代折叠的情况下进行交叉验证。以下是使用 cross_val_score 的示例:
from sklearn.model_selection import cross_val_score |
这种方法简化了代码,并提供了一种简洁的方式来执行交叉验证。cv参数指定了折叠的数量,cross_val_score负责拆分数据,训练模型并计算每个折叠的准确度。
 微信
微信 支付宝
支付宝










